Настройка мониторов в UI
Начало работы
Как создать монитор:
сверху на странице
Мониторыслева от строки поиска расположена синяя кнопка+для создания нового монитора
Как редактировать и настраивать монитор:
на странице общего списка -
Мониторы, при наведении на монитор, справа в строке появляется иконка карандаша для его редактированияна странице самого монитора, сверху справа от имени также есть карандаш редактирования этого монитора
Просматривать и настраивать мониторы в процессе эксплуатации приходится чаще, чем содавать новые, поэтому страница адаптирована для просмотра. Для создания монитора с нуля, рекомендуется начать со второго раздела Настройка групп. То есть сначала разобраться с выражением и группировкой, а затем конструировать имя и развёрнутое описание.
В процессе развертывания в систему будут импортированы как мониторы общего назначения, так и мониторы для решений Группы Астра. Их элементы настройки можно использовать как примеры.
Примечание
Требования к уровню подготовки администратора для создания монитора не так высоки. Желательно иметь общее представление о технологии экспортеров Prometheus. На базовом уровне понимать синтаксис запросов на языке PromQL/MetricsQL. При этом, не обязательно сразу уметь самостоятельно писать сложные выражения. На просторах интернет сообщества вы без труда найдёте готовые варианты запросов. Останется только протестировать выражение кандидат в интерфейсе VictoriaMetrics и выверить: какие лейблы возвращаются в ответе, какое числовое значение и какие лейблы взять для образования групп монитора.
Все обязательные поля формы помечены красными звёздочками. Работать с секциями можно в произвольном порядке, кнопка Сохранить не станет активна, пока всё обязательное не будет заполнено правильно.
Примечание
Поля Описание и Запрос могут вмещать достаточно много текста, который не помещается в них целиком. Для этого случая в правом нижнем углу предлагается контроль в виде треугольника, за который можно тянуть вниз и увеличивать их высоту. Своего рода замена полос прокрутки.
1. Общая информация
Имя монитора
Имя монитора определяет какими будут события, проблемы и оповещения. Событие (event) имеет краткое и развёрнутое описание, Summary и Description соответственно. Summary состоит из двух частей префикса и текста. Имя монитора, как шаблон, используется для создания текстовой части Summary.
Свойства префикса:
префикс зашит в код, нигде не настраивается и имеет несколько фиксированных значений
префикс указывает только на новое состояние, то есть «куда перешла группа»
префикс не должен упоминать откуда произошёл переход
префикс позволяет использовать один и тот же текст описания, придавая ему разный смысл
Префикс |
Что значит |
Когда используется |
|---|---|---|
[Triggered] |
сработало, тревога, критично |
в правилах указан порог для Critical |
[Warn] |
- предупреждение о близости к срабатыванию, к тревоге |
в правилах указан порог для Warning |
[Recovered] |
- восстановилось, отбой тревоги, всё ОК |
всегда |
[No data] |
выявлено прекращение поступления данных от группы |
только в режимах Состояние «Нет данных с оповещениями» и |
Примечание
Почему уровней критичности инцидентов в системах ITSM-ServiceDesk обычно много (например, Critical, Major, Minor, Warn, Indeterminate, Info, None и т.п.), а префиксов, которые как будто похожи на критичности, так мало и, более того, нельзя добавлять свои? Это принципиальный момент для понимания алертинга. Префиксы непосредственно связаны с оповещениями, можно сказать они управляют ими. Оповещение - это всегда тревога. Поэтому за основу принято брать минимальный набор с одним уровнем - «тревога» и «отбой тревоги», а для ситуаций, когда дествительно/обоснованно нужно предупреждать заблаговременно, к уровню «тревога» добавляют уровень «предупреждение о приблизившейся тревоге». Создание дополнительных уровней для событий привело бы росту числа оповещений в геометрической прогрессии и это совсем не то, что нужно хорошей системе мониторинга.
Язык имени монитора и его описания
Для задания имени монитора и описания используется стандартный шаблонизатор go для HTML кода - https://pkg.go.dev/html/template
Рекомендации по выбору имени
имя должно звучать, как сообщение о проблеме -
Мало места на диске ... на хосте ...,Высокий IOWAIT на хосте...Пример события из полохого имени[Warn] Процент успользования CPU...имя не должно содержать явного указания на критичность, оно должно быть нейтральным в этом отношении. Префикс отразит критичность. Пример события из полохого имени
[Warn] Критически мало места на дискепри подстановке числового значения, его место в имени следует выбирать обдуманно. Пример неправильного выбора места
[Recovered] Высокая температура 15°C в комнате 220А, а лучше будет[Recovered] Высокая температура в комнате 220А Текущее значение 15°Cследует помнить об установке требуемого количества знаков для округления значения
Примечание
В сочетании с префиксом [Recovered] и зелёным цветом индикации, текст в виде сообщения о проблеме выглядит нормально. Например, даже в самом бедном случае «бесшаблонного» имени монитора вида «Высокая температура на улице», если до этого приходило оповещение «[Warn] Высокая температура на улице», то пришедшее затем «[Recovered] Высокая температура на улице» читается достаточно понятно - ситуация с высокой температурой на улице улучшилась. Конечно, такие примитивные имена мониторов мало информативны и на практике не применяются. Монитор создан для контроля большого количества групп одновременно и без параметризации имени тут не обойтись.
Примеры событий из имени: High temperature in the room {{index .Labels "room_number"}}
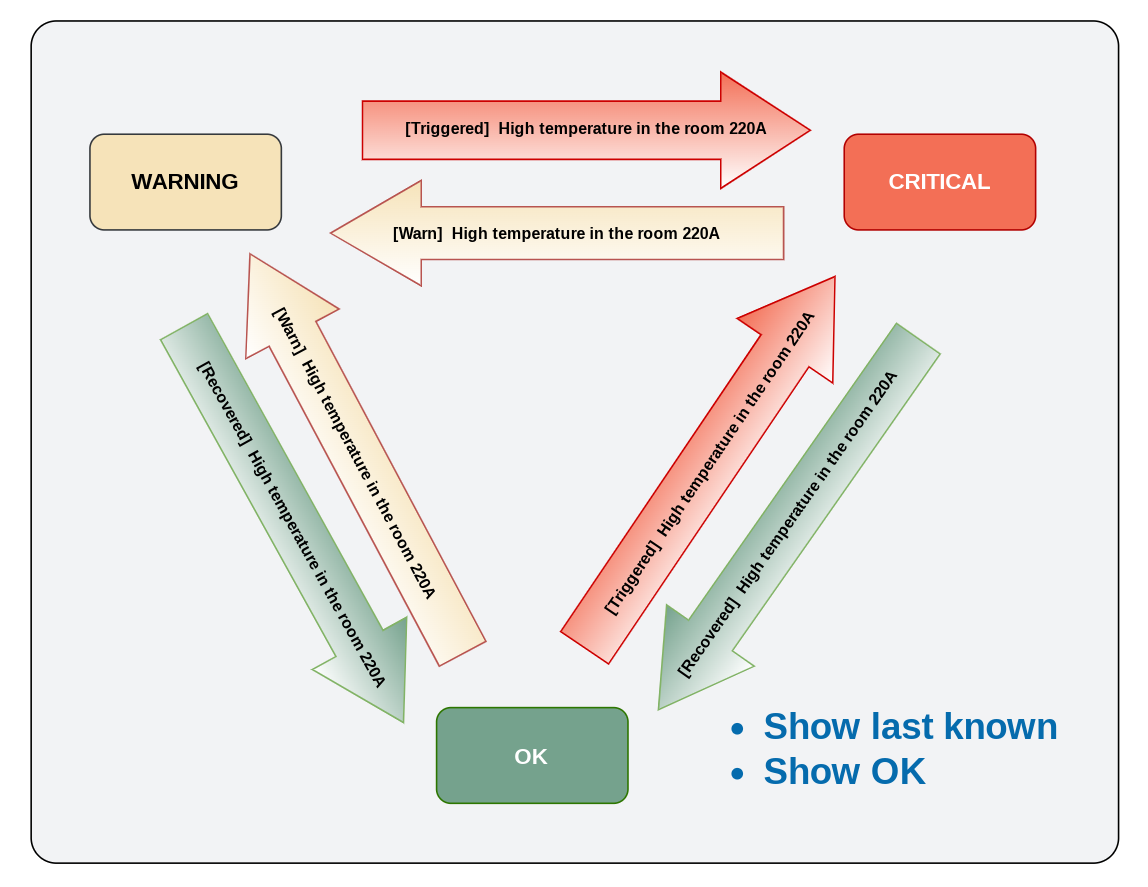
Имя монитора задаёт вид Summary всех будущих событий (этот рисунок без No data)
Ещё раз обратите внимание на то, что все события своими префиксами указывают куда изменяется состояние.
Простые имена мониторов
Пример запроса, возвращающего номера комнат с их температурами:
|
|
|
|---|---|---|
room_temperature |
220A |
26 |
Группировка: room_number
Значение этого лейбла можно адресовать в имени как {{.Group}}.
Для данного примера, с одним лейблом в качестве группировки, это эквивалентно: {{index .Labels "room_number"}}
Примеры имен и событий:
Имя монитора ( |
Пример события ( |
|---|---|
Высокая температура в комнате |
[Warn] Высокая температура в комнате 220A |
Высокая температура в комнате |
[Triggered] Высокая температура в комнате 220A, 32°C |
Высокая температура в комнате |
[Triggered] Высокая температура в комнате 220A, 32°C при пороге 30°C |
Справка:
{{.Value0}}- отбрасывает дробную часть{{.Value2}}- оставляет два знака после запятой{{.Threshold}}- подставляет значение сработавшего порога из решающего правила
Сложные имена с разделением лейблов
Пример запроса о свободном месте на диске:
|
|
|
|
|---|---|---|---|
brest.astralinux |
/run |
tmpfs |
26.353648748 |
Группировка: hostname, mountpoint
Для подобных составных имен используем отдельные лейблы:
Имя монитора ( |
Пример события ( |
|---|---|
Мало места на диске |
Мало места на диске /run на хосте brest.astralinux свободно 26.35% |
Мало места на диске |
Мало места на диске /run fs:tmpfs на хосте brest.astralinux свободно 26% |
Примечание:
{{.Host}} - это сокращение для {{index .Labels "hostname"}}. Рекомендуется использовать полную форму.
Имена с группировкой оповещений
Если будет трудно понять для чего нужна «группировка оповещений» и почему она так сильно влияет на конструкцию шаблона имени и описания, рекомендуется, забегая вперёд, прочитать об этом в третьей главе Настройка оповещений.
Другой пример запроса о свободном месте на дисках:
Значение в поле Группировка:
hostname, mountpointЗначение в поле Группировка оповещений:
hostname
Пример данных:
hostname |
mountpoint |
value |
|---|---|---|
brest.astralinux |
/mnt |
34.09 |
brest.astralinux |
/opt |
16.73 |
holod.astralinux |
/info |
76.34 |
holod.astralinux |
/ |
86.65 |
Образец названия для монитора с группами оповещений:
monitor name |
event example |
|---|---|
Мало места на дисках: |
[Warn] Мало места на дисках: holod.astralinux,/info=76% holod.astralinux./=86% на хосте holod.astralinux |
Мало места на дисках: |
[Warn] Мало места на дисках: holod.astralinux,/info holod.astralinux,/ на хосте holod.astralinux |
Примечание
Имя подгруппы всегда начинается с имени надгруппы и обязательно включает его.
Дополнительная информация
Специальные переменные:
LabelsAsString - имя метрики в формате Prometheus
Пример: node_load1{hostname="holod.local",dc="sochi"}
Group - имя группы (генерируется на основе Monitor.GroupBy)
Пример: holod.local,c:\
RuleInfo - переменная для отладки стеков правил. Выводит информацию по сработавшему правилу для этой группы.
Пример использования в имени: ...rule = {{.RuleInfo}}
Примеры для разных режимов:
Без групп оповещений (метрика hostname,mountpoint):
{{.Group}}: holod.local,/opt{{.LabelsAsString}}: disk_usage{hostname=»holod.local», «mountpoint=/opt»}{{.Name}}: disk_usage
С группами оповещений (группировка по hostname):
{{.Group}}: holod.local{{.LabelsAsString}}: {hostname=»holod.local»}{{.Name}}: holod.local
Предназначение поля Summary
Поле Summary является ключевым элементом системы уведомлений:
Главное поле в таблицах и списках событий
Заголовок (Subject) для email-уведомлений
Унифицированный идентификатор для событий одной группы
Преимущества единого формата:
Быстрое восприятие Позволяет мгновенно выделять связанные события в длинных списках
Удобство обработки Одинаковый шаблон помогает оперативно распознавать:
Срабатывания мониторов
Восстановления состояний
Повторные события
Эффективная группировка Обеспечивает визуальную связность событий одной группы
Где используются разные форматы:
Элемент |
Характеристики |
Пример использования |
|---|---|---|
Summary |
Краткий, единообразный |
«Высокая температура в комнате 220A» |
Описание |
Подробное, с дополнительной информацией |
Включает: |
Рекомендации по оформлению - Best practice
Для Summary используйте краткие неизменяемые шаблоны для событий одного монитора
Для Описаний применяйте:
подстановочные переменные
ссылки на связанные объекты
инструкции по реагированию
дополнительные метрики и данные
Важно
Единообразие Summary критически важно для эффективного мониторинга и оперативного реагирования.
Описание
В отличие от Summary, развернутому описанию события (англ. Description) для передачи смысла не требуются префиксы. Используя различные блоки условий - в зависимости от того из какого в какое состояние происходит переход - описание может использовать полностью разные предложения. Например, Summary двух разных по смыслу событий «прихода в Warning из ОК» и «возврата в Warning из Triggred» могут выглядеть одинаково, в то время как описание позволит отразить, что во втором случае мы не предупреждаем, а сообщаем об улучшении ситуации. Описание использует тот же синтаксис шаблонизатора Go, что и имя.
Примечание
Описание важное, но необязательное поле. Если оставить его пустым, монитор как Description повторит значение Summary.
Операторы ветвления в описании
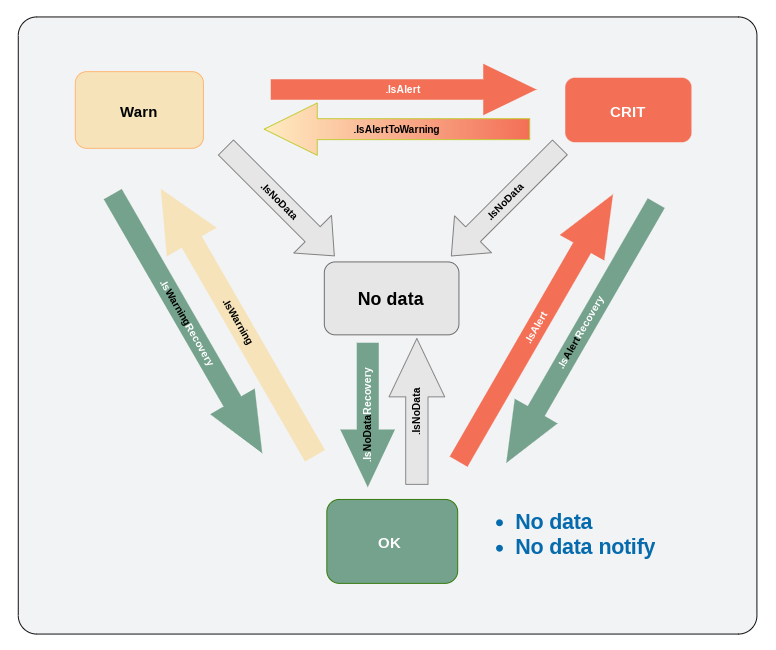
Приведём два примера заполнения поля Описание, без использования группировки оповещений и с ней.
Без группировки оповещений
Имя монитора: Мало места на диске {{index .Labels "mountpoint"}} на хосте {{.Host}} свободно {{.Value0}}%
Группировка: hostname, mountpoint
Группировка оповещений: (пусто)
{{ if .IsAlert}}<p> Критичная ситуация с оставшимся свободным местом на на диске {{index .Labels "mountpoint"}} хоста {{.Host}}, занято {{.Value}}% при пороге на ALERT {{.Threshold}}%</p>{{end}}
{{ if .IsAlertRecovery}}<p> Разрешилась бывшая критичной ситуация с местом на диске {{index .Labels "mountpoint"}} хоста {{.Host}}, занято {{.Value}}% при пороге на Recovery из АLERT {{.Threshold}}%</p>{{end}}
{{ if .IsAlertToWarning}}<p> Снизилась до Warning критичная ситуация с местом на диске {{index .Labels "mountpoint"}} хоста {{.Host}}, занято {{.Value}}% при пороге {{.Threshold}}%</p>{{end}}
{{ if .IsWarning}}<p> Тревожная ситуация с местом на диске {{index .Labels "mountpoint"}} хоста {{.Host}}, занято {{.Value}}% при пороге {{.Threshold}}%</p>{{end}}
{{ if .IsWarningRecovery}}<p> Разрешилась тревожная ситуация с местом на диске {{index .Labels "mountpoint"}} хоста {{.Host}}, занято {{.Value}}% при пороге {{.Threshold}}% </p>{{end}}
{{ if .IsNoData}}<p> Прекратилось поступление актуальных данных о диске {{index .Labels "mountpoint"}} хоста {{.Host}} </p>{{end}}
{{ if .IsNoDataRecovery}}<p> Возобновилось поступление данных о диске {{index .Labels "mountpoint"}} хоста {{.Host}}, занято {{.Value}}%</p>{{end}}
<hr>
<p>Ссылка на монитор:
<a href="http://monitoring.example.org//monitoring/monitors/{{.ID}}">
http://monitoring.example.org//monitoring/monitors/{{.ID}}
</a>
</p>
<p>Ссылка на группу метрик монитора:
<a href="http://monitoring.example.org/monitoring/monitors/{{.ID}}?group={{.MetricID}}">
http://monitoring.example.org//monitoring/monitors/{{.ID}}?group={{.MetricID}}
</a>
</p>
<p>Описание путей решения проблемы в конфлюэнс: <a href="http://example.org">http://example.org</a></p>
С группировкой оповещений
Имя монитора: Мало места на дисках: {{range .Subgroups}} {{.Name}}={{.Value0}}%{{end}} на хосте {{.Name}}
Группировка: hostname, mountpoint
Группировка оповещений: hostname
<h1>
{{ if .IsAlert}} На хосте {{.Name}} имеются диски с критически малым свободным местом {{end}}
{{ if .IsAlertRecovery}} На хосте {{.Name}} разрешилась ситуация с наличием критически занятых дисков. На всех дисках достаточно свободного места {{end}}
{{ if .IsAlertToWarning}} На хосте {{.Name}} больше нет критически загруженных дисков, но ещё остаются тревожно занятые {{end}}
{{ if .IsWarning}} На хосте {{.Name}} высокая загрузка процессора! {{end}}
{{ if .IsWarningRecovery}} На хосте {{.Name}} имеются диски, на которых становится мало свободного места {{end}}
{{ if .IsNoData}} На хосте {{.Name}} имеются диски, о которых перестали поступать данные о состоянии {{end}}
{{ if .IsNoDataRecovery}} На хосте {{.Name}} разрешилась ситуация с непоступлением данных от отдельных дисков. Все диски под контролем и на них достаточно свободного места {{end}}
</h1>
<ul>
{{range .Subgroups}}<li>{{.Name}} = {{.Value}}</li>
{{end}}
</ul>
<hr>
<h2>Статистика</h2>
<p>Группы в состоянии Сritical: {{.SubgroupsInCritical}}</p>
<p>Группы в состоянии Warning: {{.SubgroupsInWarning}}</p>
<p>Группы в состоянии NoData: {{.SubgroupsInNoData}}</p>
<p>Группы в состоянии OK: {{.SubgroupsInOK}}</p>
<p>Ссылка на монитор:
<a href="http://monitoring.example.org//monitoring/monitors/{{.ID}}">
http://monitoring.example.org//monitoring/monitors/{{.ID}}
</a>
</p>
<p>Ссылка на группу метрик монитора:
<a href="http://monitoring.example.org//monitoring/monitors/{{.ID}}?group={{.MetricID}}">
http://monitoring.example.org//monitoring/monitors/{{.ID}}?group={{.MetricID}}
</a>
</p>
<p>Описание путей решения проблемы в конфлюэнс: <a href="http://example.org">http://example.org</a></p>
Примечание
Если в описании учесть не все возможные варианты переходов, то в случае пропущенного - получится пустое описание. Однако, если в Description есть отдельно стоящие, не входящие ни в какие условные блоки тексты, они обязательно будут добавлены в каждое событие.
2. Настройки групп
В этой секции решается два главных вопроса
как получить числовое значение, которое позволит судить о состоянии объекта
что считать этим объектом
Astra Monitoring использует язык запросов Prometheus - PromQL и его расширение от VictoriaMetrics - MetricsQL.
Для настройки этой секции, желательно понимать отличия следующих двух типов функций этого языка:
Функции обработки временных рядов - обобщают множество значений одного объекта во времени
Агрегационные функции: Используются для вычисления различных статистических показателей (сумма, среднее, минимум, максимум и т.д.) по заданному временному интервалу. Примеры:
sum(),avg(),min(),max(),count().Функции для работы с окнами (Rollup functions): Позволяют обрабатывать данные в скользящих окнах, что полезно для вычисления трендов, сглаживания данных и т.д. Примеры:
rate(series_selector[d])для counters иavg_over_time(series_selector[d])для guages,moving_avg(),moving_sum(),moving_min(),moving_max(). Документация на Rollup функции VictoriaMetrics
Функции для работы с лейблами
Функции для фильтрации: Используются для выбора подмножества метрик по значениям лейблов. Примеры:
metric_name{label1="value1", label2="value2"}(фильтрация по лейблам).Функции для группировки по лейблам (Aggregate functions) Их используют, чтобы отразить состояние логически большего объекта, обобщая значения множества входящих в него меньших объектов. Они позволяют группировать данные по значениям лейблов, что удобно для анализа данных по различным категориям. Примеры:
avg(q) by (group_labels),count_over_time(q) by (group_labels),sum(metric_name) by (label1, label2).
Документация на Aggregate функции VictoriaMetrics
Запрос - Query
Функции обработки временных рядов следует использовать в конструкции Запроса. Необходимые вычисления будут выполнены самой VictoriaMetrics.
Примечание
В настоящее время AM самостоятельно не делает агрегацию по времени. Если она нужна, то следует включать её в запрос. Чтобы удостовериться, что у вас правильный Instant vector запрос (возвращающий одно значение для каждого ряда), можно проверить его на странице Metrics Explorer в VictoriaMetrics.
Функции работы с лейблами, касающиеся фильтрации, следует также применять в выражении, а функции группировки по значениям лейблов, напротив, желательно и безопасно делать в АМ. Под безопасностью имеется ввиду защита от дубликатов объектов в мониторе.
Примечание
Группировку по сочетанию лейблов правильно делать не в выражении, а в настройке монитора в поле «Группировка». Фильтрацию по значениям лейблов задают в выражении.
Примеры выражений для поля Запрос.
(100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100))
share_eq_over_time(systemd_unit_state_id{name=~"apache2.service|rabbitmq-server.service|postgresql@.*.service", product="ald-pro", component="repositoring"}[5m], 1) * 100
((node_filesystem_avail_bytes{device!~"rootfs",mountpoint!~"/etc/hostname",mountpoint!~"/etc/resolv.conf",mountpoint!~"/etc/hosts"} * 100) / node_filesystem_size_bytes{device!~"rootfs",mountpoint!~"/etc/hostname",mountpoint!~"/etc/resolv.conf",mountpoint!~"/etc/hosts"} and ON (instance, device, mountpoint) node_filesystem_readonly == 0) * on(instance, hostname, job, group) group_left (nodename) node_uname_info
Обратите внимание, что первое и третье выражение не используют Rollup функции, а второе её использует в виде share_eq_over_time(series_selector[d], n).
Группировка
Агрегирование бы точнее передавало смысл этой настройки, но для UI название «группировка» подходит больше и, что самое главное, оно напрямую указывает на её связь с группой монитора, как объектом наблюдения.
Примечание
По определению ИИ: «В общем смысле агрегировать означает объединять, соединять отдельные элементы или данные в единое целое, более крупную единицу или систему. Это процесс приведения множества разрозненных данных к более компактному и обобщенному виду, часто для упрощения анализа или управления.»
В случае запросов к TSDB, разрозненные данные это когда для заданного объекта/группы получаем в ответе множество строк с разными числовыми значениями. Вот их и нужно объединить, взяв, например, среднее, максимальное, минимальное, сумму, посчитать их и т.п., чтобы получить строго по одному объекту в ответе.
Группировка решает три задачи:
задаёт какое сочетание лейблов считать названием группы (отдельным объектом, наблюдаемым монитором)
указывает какое математическое действие следует применить к множеству элементов ответа для одной группы
гарантирует уникальность всех записей в ответе (отсутствие дубликатов объектов)
Группировка по лейблам в полном объёме поддерживается языком запросов. Однако, с группировой в конструкции by() мы обязаны перечислить все лейблы, значения которых нам будут важны. Все не упомянутые по имени лейблы будут обязательно отброшены, даже если для этой группы они все имеют одинаковые значения.
В качестве источника данных для следующих примеров возьмём последнее выражение из примеров выше. Оно возвращает процент занятого места на точках монтирования разных хостов (mountpoints/условно дисках). Ограничимся сокращённым набором лейблов и будем называть всё это выражение как used_space.
Предположим, что задав в запросе used_space, мы получили такой ответ.
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
aquilla01 |
nagatinskaya |
prod |
dc02.local |
/dev/mapper/vg0-root |
ext4 |
36.665054 |
aquilla29 |
ostankino |
test |
dc03.local |
/dev/mapper/vg0-home |
ext4 |
39.737389 |
aquilla02 |
nagatinskaya |
prod |
dc02.local |
/run/tmpfs |
tmpfs |
11.838383 |
dev |
ostankino |
prod |
dc05.local |
/opt |
ext4 |
87.949494 |
Примечание
Это Instant vector запрос, когда каждому уникальному сочетанию лейблов соответствует одно последнее доступное значение. Указываются последние «снятые» значения, и у записей нет временных меток. Range vector же показывает значения каждого объекта в разные моменты времени.
Например, если дать запрос avg(used_space) by (hostname), то получим такой ответ с одним лейблом
|
|
|---|---|
dc02.local |
24.2517185 |
dc03.local |
39.737389 |
dc05.local |
87.949494 |
Получено по одному значению для каждого хоста. При этом для обеспечения уникальности группы только для dc02.local потребовалось усреднить значение двух разных рядов, а два других dc03 и dc05 так и были в единственном числе, для них ничего не усреднялось. Получается, что никакие лейблы хостов dc03 и dc05 можно было не отбрасывать (при этих конкретных исходных данных). Но и у хоста dc02.local можно было сохранить значения лейблов location и environment, поскольку их значения одинаковые у обоих связанных с dc02 рядов.
Встроенная в АМ группировка по лейблам отличается индивидуальным подходом с максимальным сохранением лейблов каждой группы.
Алгоритм группировки АМ:
для каждого уникального сочетания перечисленных в
Группировкалейблов рассматривается ответесли вернулась одна строка, то все её лейблы передаются в ответ
если вернулось несколько строк, то
все лейблы, имеющие одинаковые значения во всех этих строках, передаются в ответ со своими значениями
все лейблы, имеющие хотя бы одно отличающееся значение среди этих строк (конфликтуют), отбрасываются
Таким образом в АМ, отбрасываются только лейблы, по которым действительно произведено «укрупнение», не теряется никаких полезных лейблов, не потеряются и те, которые добавят в будущем.
Важно
Принудительное Агрегирование значений в группы - это основополагающая и обязательная функция группировки по лейблам в АМ. Какое бы выражение вы не поместили в поле запрос, вы начнёте с того, что получите одну группу с именем Entire infrastructure и одним числовым значением. Система не позволит вам очистить это поле. Не агрегировать совсем нельзя по определению.
Как только вы встанете на поле Группировка, предзаполненое как Entire Infrastructure, система подскажет вам варианты, предложив на выбор только те лейблы, которые присутствуют во всех строках ответа на запрос. То есть те, которые вообще имеют право стать группообразующими.
Перед тем как указать сочетание лейблов в группировке, советуем определиться что будет объектом «на самом низком уровне». Например, будет ли это диск сервера или сервер целиком, будет ли это каждый датчик температуры в комнатах или комнаты целиком, каждый порт маршрутизатора или сам маршрутизатор. Далее важно ответить на вопрос возможны ли в инфраструктуре объекты с такими же именами. Если невозможны, то этот лейбл и взять в качестве имени группы. Если возможны, то проанализируйте добавление каких лейблов логично обеспечит уникальность объектов и добавьте их в начало имени.
Примеры:
hostnameотлично подходит для экспортера утилизации CPU, который пишет по каждому ядру отдельноhostnamemountpoint- когда мы хотим знать на каком именно диске кончается место, мониторить индивидуально каждый дискenvironmenthostnamemountpoint- если у нас несколько окружений и в них есть хосты с одинаковыми именами, перехлёстывающиеся пространства имён или IP адресов
Примечание
Если в процессе развития, у вас появятся более крупные группообразующие лейблы, например появятся перехлёстывающиеся пространства имён, не забудьте включить эти лейблы в группировку монитора. Иначе, сами того не осознавая, вы станете получать среднее значение для одинаковых объектов разных окружений.
Агрегация
Вибираете что делать при агрегации. avg(default), max, min, sum, count.
Период обновления монитора
Интервал времени с окончания предыдущей проверки и инициации новой. Например 1m 10m 1h
Шаг
У этой настройки два назанчения:
с таким шагом отрисовывается справочный график
это реальная величина
stepв запросе, если выражение не использует Rollup, то есть оно Instant vector запрос, step позволяет установить, что считать отсутствием данных.
Примечание
Предустановленный шаг 5 минут подходит для большинства ситуаций и можно его оставить как есть. У нас нет экспортеров со скрейпингом реже 1м. Если ваше выражение записывает данные реже одного раза в 5м, нужно увеличить шаг.
График
График приводится только для подсказки, чтобы дать представление, что вы правильно создали запрос и настроили группировку.
График отображает не настраиваемые:
за последний час
не более и первые 10 групп в порядке как вернула VictoriaMetrics
Помогает в процессе настройки увидеть:
что правильно задана группировка и что имена групп в таком виде вас устраивают
как ведут себя значения, чтобы потом при настройке правил иметь представление какие числа использовать как пороги
3. Настройки оповещений
Это не обязательная для заполнения секция. Если оставить её пустой, никаких оповещений отправляться не будет.
Но в ней есть очень важный элемент, который, если его с пониманием настроить, изменит не только смысл/характер оповещений, но в корне изменит отображение состояния монитора. Это группировка оповещений.
Группировка оповещений
При фокусе на этом поле на выбор предлагаются лейблы, которые установлены в поле Группировка. И если их несколько, а при одном группировка оповещений бессмысленна, то выбирать нужно от самого крупного к более мелкому.
Примечание
Включение группировки оповещений требует изменения формата имени и описания монитора.
При включении группировки оповещений, появится новая логическая сущность Надгруппа, берущая на себя роль группы в плане инициации событий и оповещений. Далее она будет делать это от своего имени. Хотя и возьмёт себе право называться Группой, теперь она будет нести другой смысл. Эти новые группы не будут иметь значений и будут отображаться на главной странице монитора вместе со статистикой состояний своих подгрупп. Изначальные же группы теперь станут Подгруппами своей Группы, они будут отображаться если в надгруппу войти. Подгруппы будут иметь значения и будут иметь состояния на диаграмме, но не будут иметь своих событий и оповещений соответственно.
Как группа оповещений определяет своё состояние?
Состояние группы определяется по максимальной критичности среди её подгрупп. По приоритету в следующем порядке: Crit, Warn, No data, OK. Сколько каких не имеет значения, если будет одна красная и 10 желтых, то группа будет красная. Значения как такового у неё нет, а есть состояние и знание состава и статистики состояний своих подгрупп.
Создаётся ли событие при смене состава подгрупп, задающих текущую критичность группы оповещений?
Нет, события не будет. И в этом смысл агрегации оповещений. Один дополнительный к уже имеющемуся пришёл, один ушёл - не важно и не стоит упоминания как события. При этом, судить о том, что количество влияющих подгрупп изменилось, мы сможем по статисктике групп на странице монитора и детально на странице данной подруппы.
Сколько уровней подгрупп можно сделать?
Только два. Одна надгруппа может включать несколько подгрупп, а у подгрупп в принципе не может быть своих подгрупп. Устанавливая значение Группировка оповещений из группобразующих лейблов в настройке Группировка, мы как бы задаём линию раздела - где группа генерирующая события и оповещения, а где подгруппы, имеющие только состояния, значения и влияние на группу. Далее на примерах это станет понятнее. Таким образом мы как бы разрезаем группировку на две части и переподключаем механизм оповещений к получившейся первой (логической, искусственной) части - к надгруппе.
Изменятся ли имена подгрупп?
Нет, имена подгрупп остаются в неизменном и полном виде, то есть включают в себя и начинаются с имени своей надгруппы.
Примеры для гипотетической задачи контроля температуры на разных площадках с датчиками
Одно правило >= 24 Warning, >= 26 Critical
|
|
|
|
|---|---|---|---|
Варшавское |
Главный |
AB898 |
23.3 |
Варшавское |
Главный |
GB776 |
22.5 |
Варшавское |
Резервный |
AB898 |
25.3 |
Варшавское |
Резервный |
GB776 |
21.3 |
Огородный |
Главный |
AA2222 |
26.3 |
Огородный |
Главный |
BB4444 |
24.1 |
Огородный |
Резервный |
AB111 |
22.8 |
Огородный |
Резервный |
AA8888 |
- |
Усады |
Основной |
JK332 |
25.2 |
Усады |
Основной |
BF768 |
- |
Примечание
Прочерк в поле значения температуры сенсора поставлен для наглядности. На самом деле, если нет данных от сенсора, этой строки просто не будет в ответе на запрос. Однако, монитор отслеживает эту ситуацию и, как увидите дальше, знает его текущее состояние как No data.
Вариант 1 Группой и фокусом внимания будет каждый ЦОД
|
Основная |
|---|---|
site, datacenter |
site, datacenter, sensor_id |
|
|
|
|
|
|
|---|---|---|---|---|---|
Варшавское,Главный |
OK |
- |
Варшавское,Главный,AB898 |
OK |
23.3 |
Варшавское,Главный, GB776 |
OK |
22.5 |
|||
Варшавское,Резервный |
Warn |
- |
Варшавское,Резервный,AB398 |
Warn |
25.3 |
Варшавское,Резервный,GB793 |
OK |
21.3 |
|||
Огородный,Главный |
Crit |
- |
Огородный,Главный,AA2222 |
Crit |
26.3 |
Огородный,Главный,BB4444 |
Warn |
24.1 |
|||
Огородный,Резервный |
No data |
- |
Огородный,Резервный,AB111 |
OK |
22.8 |
Огородный,Резервный,AA888 |
No data |
- |
|||
Усады,Основной |
Warn |
- |
Усады,Основной,JK332 |
Warn |
25.2 |
Усады,Основной,BF768 |
No data |
- |
Имя монитора
Высокая температура в ЦОД {{.Group}} по сенсорам {{range .Subgroups}} {{.Name}}={{.Value0}}°C{{end}}
Примеры Summary событий для имени монитора
[Triggered] Высокая температура в Огородный,Главный сенсоры Огородный,Главный,АА2222=26.3°C
Ситуация, когда надгруппа Огородный,Главный из исходного Crit состояния обусловленного совокупным влиянием сенсоров - A2222:Crit,B444 и A9::Warn, A12:OK, из-за охлаждения зоны сенсора А2222 до Warn вся преходит/опускается до Warn.
[Warn] Высокая температура в Огородный,Главный сенсоры Огородный,Главный,АА2222=25.8°C, Огородный,Главный,B4444=24.1,Огородный,Главный,A9=24,3°C
Примечание
Детально настроив шаблон описания для случая перехода isAlertToWarning мы получим информацию, что это улучшение ситуации, а не её ухудшение
Вариант 2 Группой и фокусом внимания будет площадка (site)
|
Основная |
|---|---|
site |
site, datacenter, sensor_id |
|
|
|
|
|
|
|---|---|---|---|---|---|
Варшавское |
Warn |
- |
Варшавское,Главный,AB898 |
OK |
23.3 |
Варшавское,Главный, GB776 |
OK |
22.5 |
|||
Варшавское,Резервный,AB398 |
Warn |
25.3 |
|||
Варшавское,Резервный,GB793 |
OK |
21.3 |
|||
Огородный |
Crit |
- |
Огородный,Главный,AA2222 |
Crit |
26.3 |
Огородный,Главный,BB4444 |
Warn |
24.1 |
|||
Огородный,Резервный,AB111 |
OK |
22.8 |
|||
Огородный,Резервный,AA888 |
No data |
- |
|||
Усады |
Warn |
- |
Усады,Основной,JK332 |
Warn |
25.2 |
Усады,Основной,BF768 |
No data |
- |
Имя монитора Изменяем имя, чтобы события звучали как для сайта.
Высокая температура в ЦОД района {{.Group}} по сенсорам {{range .Subgroups}} {{.Name}}={{.Value0}}°C{{end}}
Примеры Summary событий для имени монитора
[Triggered] Высокая температура в ЦОД района Огородный сенсоры Огородный,Главный,АА2222=26.3°C
Получается, что в событиях мы часто не будем видеть всех актуальных влияющих групп на данный момент. А бывают ли исключения?
Да, бывают. Во первых, если одновременно сработали две и более групп и перевели надгруппу на другой уровень, то мы увидим их все. И ещё, когда последняя группа снижается с Crit до Warn, а там уже сеть несколько Warn (они до этого не влияли на состояние надгруппы), то в событии будут перчисленны все в результате оказавшиеся в Warn подгруппы.
Использовать политику оповещений
Кнопка-трейлер к функционалу будущего релиза. Эта кнопка размещена здесь умышленно. Она для того, чтобы вы имели ввиду, что идёт работа над глобальной настрокой оповещений на уровне политики и вскоре её можно будет настраивать и включать. Пока эта кнопка не активна и это не баг.
Канал оповещений
Здесь мы должны выбрать один (пока только один для монитора) из преднастроенных через seed файл каналов. Это временное ограничение и скоро будет любая комбинация Contact points.
Получатели оповещений (только для email)
Это поле заполняется только, если выбран канал оповещений E-mail. Через запятую указываются e-mail адреса получателей. Это временное решение, впоследствии это уйдёт в настройку именованных contact points.
Пока нет контроля по каким критичностям отправлять оповещения, а по каким нет.
4. Настройки NoData
Режим отображения No Data
На что влияет режим No data
Важно
При рассмотрении всех режимов No data нужно помнить, что
обычные штатные срабатывания Triggered, Warn и восстановления Recovery не подчиняются и не затрагиваются режимами No data. При возобновлении поступления данных, «на выходе» из состояния, они срабатывают как обычно, но есть особенности, описанные ниже для каждого режима.
отработка ситуации No data начинается спустя интервал задержки, заданный в поле Задержка обработки No data, по дефолту он ставится 10 минут. Если остановили подачу данных, то увидите это не сразу.
Для объяснения логически разделим вход в ситуацию после истечения времени задержки (и всё ещё отсутствия данных) и выход из ситуации, как только приход данных возобновится.
Действия для каждого входа и выхода описаны по следующему шаблону:
Диаграмма - влияние на полосу группы на диаграмме
Событие - какое событие записывается
Проблема - как изменяется существующая проблема и создаётся ли новая
Уведомление - отправка или не отправка уведомления
Четыре режима отработки ситуации прекращения поступления данных по группе
Последнее известное состояние (Default mode)
Смысл этого режима в том, чтобы не обращать внимания на сам факт прекращения прихода данных, не показывать вида, притворяться, изображать, что всё без изменений - «как было, так и есть». Это значит, не только не создавать событие, проблему и не оповещать об этом, а не закрывать существующую по этой группе активную проблему, если она есть. В общем, ничего не менять в отображении проблем в расчёте на веру/предположение, что во время отсутствия данных, ситуация остаётся как была. Используется, когда отсутствие данных от группы совсем не значит, что она «не работает», когда такое случается часто и повода каждый раз поднимать тревогу в таких случаях нет.
Посмотрите на первую диаграмму на этой странице, где речь идёт о температуре в комнате 220А. На ней видно, что режим предполагает полное остутсвие в нём состояния No data. Группа монитора в этом режиме никогда не бывает серой - не бывает в состоянии No data, поскольку его нет. На диаграмме не может быть серого цвета как не бывает и событий с префиксом [No data].
Состояние OK «сделать принудительный Resolve группе и закрыть проблему»
Вообще, Show OK и Show last known оба про то, что не нужно «делать проблему из прекращения прихода данных». Только режим Show OK категоричнее «в своей оптимистичности» чем Show Last known. При No data он диктует закрыть проблему, забыть о ней и не оповещать о пропадании данных. Звучит как «Нет данных - нет проблемы», а когда данные пойдут, начать «жизнь с чистого листа».
Состояние «Нет данных с оповещениями» Показывать No data и создавать проблемы
Здесь задумано так, чтобы сообщить о самом No data, создать тематическую новую No data проблему или обновить критичность существующей до No data, а также уведомить о ней. Как было сказано выше, здесь No data это полноценный отдельный уровень критичности.
Этот режим предполагает, что в схеме переходов монитора есть полноправное состояние No data, соответственно на диаграмме может быть серый цвет и будут события с префиксами [No data].
Состояние «Нет данных без оповещений»
Принцип тот же, что и No data notify, только уведомлений о No data не отправляется совсем. А серые цвета есть.
Задержка обработки No Data
Задержка, после которой инициируются действия по отработке ситуации No data. Рекомендовано 10 минут, для выражений пятиминутного охвата или без агрегации окна. Но если ваше выражение использует Rollup window, например в 1 час [1h], то этот интервал желательно выставить, как удвоенное время окна - т.е. в случае примера в 2 часа.
Удалить группу в состоянии «нет данных» через
Время через которое монитор забудет о группе, не присылающей данные. Вне зависимости от выбранного режима, «считающиеся почившими» группы удаляются из кеш монитора и как следствие
исчезают из диаграммы групп,
исчезают из событий страницы монитора
их проблемы закрываются.
Если впоследствии они возродятся, то начнут новую жизнь.
Примечание
Но что замечательно, когда «удалённые» возвращаются, то подтягивается всё их прошлое в диаграмме и их события
Важно
Отличительной способностью Astra Monitoring является сохранение состояния метрики в момент опроса. Во всемя сбоев сетевой связности, метрики могут не иметь возможности оперативно поступать на сервер в TSDB. Чтобы не допустить потери данных, предусмотрено их кешировние на агенте в течение значительного времени, 30 минут по дефолту. После восстановления сети метрики досылаются в базу данных и если после этого сделать запрос к временным рядам объектов, картина будет выглядеть так, будто никакого сетевого сбоя и не было, что данные поступали равномерно. График метрики покажет непрерывную линию и мы не сможем судить о плохой надёжности связи с объектами мониторинга. Но Event Processing AM помнит всё. Он ведёт свои временные ряды «в реальном времени = в момент опроса» и о получаемых из выражения данных, и о состояниях групп, включая все периоды No data. Глядя на диаграммы групп монитора в прошлом, мы всегда будем видеть периоды, когда монитор пребывал в состоянии отсутствия данных от группы. Такую способность вы вряд ли найдёте в Prometheus подобных системах.
5. Правила
При всей кажущейся простоте этой секции, здесь кроется особая гибкость и мощь мониторов AM.
Главные черты
поддержка стека правил с привязкой по лейблам, который работает как многоступенчатый сортировочный конвейер и позволяет а рамках одного монитора, в зависимости от значений лейблов, селективно применять правила с совершенно разными условиями и даже типами
поддержка как симметричных, там и асимметричных двухуровневых правил, и любых одноуровневых, разумеется
Важно
Вы не можете создать монитор без хотя бы одного правила либо с пустым или незаполненным правильно правилом.
В зависимости от того, что вы заполнили в четырёх полях числовых значений АМ автоматически определяет, какой тип правила будет создан. В процессе заполнения порогов система подскажет вам, где вы ошибаетесь и что введённые данные неверны - выделит красными рамками.
Правила делятся на
одноуровневые - только один порог, или Crit или Warn
двухуровневые - задействованы оба порога
симметричные - один или оба порога на срабатывание совпадает с порогом/ами на Recovery. Возможно всего три варианта: Crit, Warn, Crit+Warn
асимметричные - пороги на Recovery выставлены дополнительно (это опция), задают более строгие требования на Recovery. Также три варианта
Важно
При асимметричном варианте, в зависимости от выбранного типа сравнения, нужно обязательно учитывать, что порог на восстановление не может быть выставлен «слабее» порога срабатывания. Например, если порог для температуры на Crit 30°C, то порог на Recovery разумеется должен быть ниже (напр. 25°C).
Примечание
Техники бы назвали это свойством гистерезисом.
Гистерезис - это явление, когда система не сразу реагирует на изменение внешних условий, а как бы «запоминает» предыдущее состояние, что приводит к разнице в ее поведении при увеличении и уменьшении воздействия.
Асимметричное правило как бы диктует условие, что вернуться в нормальное или Warn состояние будт сложнее, требования будут более высокими.
Наблюдаемое значение должно быть >= (default) или <= (когда активно) указанного порога
Определяет будет ли это прямой или реверсный режим логики работы оценки. А по-простому, если,
когда больше - это в сторону хуже, то это дефолтный режим >=. Он действет, когда контроль серый и на нём написано >=
например, чем больше числовое значение температуры, тем хуже хуже. Это дефолтное поведение и пороги будем выставлять соответственно Warn должен быть обязательно меньше Critкогда меньше - это в сторону хуже, в этом случае всё наоборот
Значки выбранного условия сранения дублируются перед каждым полем ввода значения
Примечание
Планируется реализовать полный набор возможных условий сравнения: >,<,>=,<=,=,!=
Пока же наличие только двух вариантов не накладывает ограничений ни на какие готовые мониторы и, зная как работать с MetricsQL в выражении запроса, всегда можно выйти из положения.
Обязательные лейблы
Лейблы имя=значение, точнее группы с такми значениями лейблов, на которые будет влиять настраиваемое правило. Если у вас только одно правило вряд ли имеет большой смысл заполнять это поле (накладывать ограничения в нём). Ведь все созданные мониторм группы, которые не попадут под условия по заданным лейблам, просто никогда не будут срабатывать. Теоретически можно представить, что это может кому-то понадобитья, чтобы смотреть на текущие числовые значения таких вечнозелёных групп. Но на практике не используется.
Забегая вперёд скажем, что правило применется к группе при первом же совпадении по лейблам. Низлежащие в стеке правила, которые тоже могут удовлетворять этой группе, не «выполняются».
Примечание
Для обеспечения слективного воздействия монитора в целом используйте фильтр в самом выражении запроса вида q{environment="dev"}
Исключить лейблы
По аналогии. Это лейблы, на которые НЕ будет влиять правило.
Если группа не соответствует обязательным и исключённым лейблам, то «рассмотрение её дела» предаётся на следующее лежащее под ним в стеке правило. И так далее.
+ Новое правило
Важно
Операции со стеком правил пока недоступны и добавление правила погашено - dimmed. Тем не менее, для полноты картины, рекомендуем прочитать это описание, чтобы быть готовыми к использованию этой важной функции.
Добавляя новое правило, вы можете создать стек из правил. Построить своего рода сортировочный конвейер с селективным применением правил. Движение по конвейеру идёт сверху вниз.
Примечание
Только что добавленное правило попадает в самый низ стека и помечается красными скобками, чтобы подчеркнуть его временный «неперемещаемый» статус. Вы можете заполнить всё для него необходимое, но поднять на другую позицию в стеке вы пока не сможете. Нужно сохранить монитор и вернувшись в его редактирование переместить (drag&drop) это правило на нужное место и тем самым задать ему нужный вам приоритет.
Рассмотрим пример, в котором нам нужно для монитора процента использованного места на диске (mountpoint), в зависимости от расположения объекта, применить разные требования:
для prod окружения площадки «огородный» - самые строгие требования
для prod окружений всех остальных (и даже не указанных) площадок менее строгие, при этом исключить product = brest, на него пусть действую дефолтные для организации пороги
для всех остальных = любых окружений, не зависимо от площадок, применить дефолтные слабые требования
Допустим ментрика показывает процент занятого места. Логично, что чем меньше будет значение порога, тем строже правило. Оно начнёт поднимать тревогу раньше других.
Перетаскивание правил
Нажав в любом пустом месте области правила можно его перетащить вверх или вниз по стеку. Тем самым поменять порядок прохождения «конвейера». Как уже было сказано, правила «примериваются» и применяются по порядку сверху вниз.
При перемещении правил, нужно всегда помнить, что если найдено совпадение по лейбла, все правила ниже ИГНОРИРУЮТСЯ. Так, если мы перетащим нижнее правила из примера, на самый верх, то все остальные вообще никогда не будут работать. Первое правило просто «поймает» все группы монитора.
Мощь стека правил в том и заключается, что нам не нужно создавать разные мониторы для разных правил и ещё, что нам не нужно в этих мониторах явно указывать что исключить.
Чтобы проиллюстрировать это, приведём пример трёх примитивно устроенных мониторов, в которых возможно всего по одному правилу, а фильтр задаётся на этапе определения метрики.
Согласитесь, выглядит как пергруженное дублирующей информацией и трудно поддерживаемое решение.
Важно
Поддержка стека правил в комбинации с их асимметричностью - уникальная черта Astra Monitoring
Сохранить
Кнопка сохранить не станет активна до тех пор, пока все обязательные поля не будут корректно заполнены.
Отменить
В правом верхнем углу страницы есть крестик, который выполняет ту же задачу.
Важно
Изменение настроек монитора - это важное, затрагивающее все аспекты его работы событие. Каждое нажатие кнопки «Сохранить» заставляет монитор полностью пересчитать (перосмыслить) своё состяние - очистить кеш, создать новые группы, задействовать новый стек правил. Единственный способ сохранить целостность работы монитора, это закрыть все активные проблемы и начать жизнь с читсого листа. Это процедура, требующая значительных ресурсов и изменения кеша данных. На некоторое время монитор станет недоступен - будет отображаться без групп и отсутсвовать в списке мониторов. Обычно не более минуты. Относитесь с пониманием к этому его состоянию, это не дефект кода АМ, это нормально. Изменяйте и сохраняйте мониторы без суеты, обдуманно и с пониманием дела.